numl - Uma biblioteca para facilitar o uso de machine learning em .NET
Introdução
Inteligência artificial não é fácil, exige muito estudo e profundo conhecimento científico. Aliás, para ser especialista (de verdade) em qualquer coisa é necessário estudo e conhecimento científico (teórico). Porém, como e por onde começar?
Machine Learning
Muito se fala sobre Machine Learning (aprendizado de máquina), um dos ramos da inteligência artificial, que permite ao computador “aprender”, ou melhor, permite que o computador melhore seu desempenho em alguma tarefa.
Muitos programadores (isso inclui a mim) tem a terrível necessidade de experimentar antes de entender. É algo quase que automático. Se você também é um desses, este post é para você.
Neste post apresento uma introdução sobre a biblioteca criada por Seth Juarez com o objetivo de auxiliar o uso de algoritmos comuns de machine learning com a plataforma .NET. Esta biblioteca chama-se numl. Pela simplicidade e alto nível de abstração dessa biblioteca, fica claro que o objetivo de Seth é quebrar a barreira da iniciação para iniciante. Mesmo que você não entenda os principais algoritmos utilizado em machine learning (Similaridade de Cosseno, Distância de Hamming, entre outros), é possível, com poucas linhas criar um programa para prever alguma coisa.
Um exemplo
O exemplo proposto aqui, tem base no exemplo criado por Seth, porém, complementei com uma previsão. O objetivo é prever se correrá um jogo de tênis, dadas as condições climáticas. Tomei a liberdade de traduzir a estrutura para português, para facilitar ainda mais o entendimento.
Todo o código desse exemplo pode ser encontrado no meu github
A seguir, a estrutura do dado que formará o modelo de previsão. A classe Tennis é o nosso fato.
namespace Data
{
public enum Perspectiva
{
Ensolarado,
Nublado,
Chuvoso
}
public enum Temperatura
{
Baixa,
Alta
}
public class Tennis
{
[Feature]
public Perspectiva Perspectiva { get; set; }
[Feature]
public Temperatura Temperatura { get; set; }
[Feature]
public bool VentoForte { get; set; }
[Label]
public bool OcorreUmJogo { get; set; }
public static Tennis[] GetData()
{
return new Tennis[] {
new Tennis { OcorreUmJogo = true, Perspectiva=Perspectiva.Sunny, Temperatura = Temperatura.Low, VentoForte=true},
new Tennis { OcorreUmJogo = false, Perspectiva=Perspectiva.Sunny, Temperatura = Temperatura.High, VentoForte=true},
new Tennis { OcorreUmJogo = false, Perspectiva=Perspectiva.Sunny, Temperatura = Temperatura.High, VentoForte=false},
new Tennis { OcorreUmJogo = true, Perspectiva=Perspectiva.Overcast, Temperatura = Temperatura.Low, VentoForte=true},
new Tennis { OcorreUmJogo = true, Perspectiva=Perspectiva.Overcast, Temperatura = Temperatura.High, VentoForte= false},
new Tennis { OcorreUmJogo = true, Perspectiva=Perspectiva.Overcast, Temperatura = Temperatura.Low, VentoForte=false},
new Tennis { OcorreUmJogo = false, Perspectiva=Perspectiva.Rainy, Temperatura = Temperatura.Low, VentoForte=true},
new Tennis { OcorreUmJogo = true, Perspectiva=Perspectiva.Rainy, Temperatura = Temperatura.Low, VentoForte=false}
};
}
public override string ToString()
{
return string.Format("Perspectiva: {0}, Temperatura:{1}, VentoForte: {2}", Perspectiva, Temperatura, VentoForte);
}
}
}
De acordo com a nossa estrutura acima, as informações necessárias para prever se ocorrerá um jogo de tênis, são: Perspectiva, Temperatura e VentoForte, essas são chamadas de características (Features).
A informação que desejamos prever (OcorreUmJogo), são chamadas de Label (entiqueta).
A previsão
Os tipos mais básicos de aprendizado de máquina são: o supervisionado e não supervisionado. O supervisionado (o que utilizaremos como exemplo), encontra padrões sobre um conjunto de fatos apresentados, basicamente classifica a informações etiquetando-a; o não supervisionado a máquina se esforça para aprender sobre os fatos, neste caso, os fatos não são apresentados previamente, porém esses são informados em grande volume, o que permite a previsão/classificação.
Para prever se ocorrerá um jogo, para dadas características, devemos seguir alguns passos:
1. Apresentamos os fatos ao algoritmo
A primeira tarefa é aprender sobre esses fatos (reconhecer padrões). A linha a seguir, inicia o treinamento:
var learned = Learner.Learn(data, 0.80, 1000, generator);
Acima, o treinamento para nossa máquina de prever se ocorrerão jogos de tênis dadas as condições climáticas. O primeiro argumento são os fatos sobre jogos de tênis anteriores; o segundo é o percentual da massa de dados que será utilizada para treinamento; logo após, o terceiro, é a quantidade de vezes que esse treinamento será executado sobre os dados; e por fim, o quarto argumento, é o modelo escolhido para que o aprendizado seja armazenado, esta será a estrutura de dados utilizada para raciocinar e prever os próximos jogos, a árvore de decisão.
Após aprender, imprimimos esta árvore, apenas para entendermos o que foi aprendido:
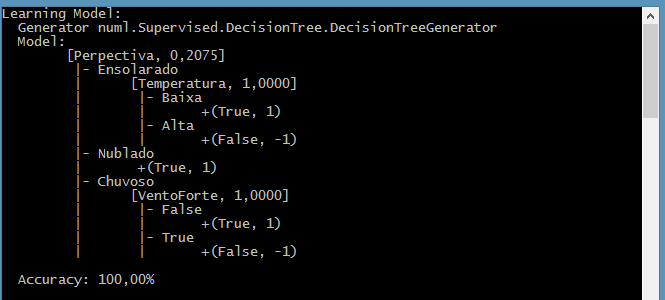
A árvore acima nos mostra de uma forma simples e clara os padrões que existem nos fatos informados. Por exemplo, é possível percebe que sempre que a Perspectiva for Nublado, independente da Temperatura, sempre ocorrerá um jogo. E também é possível perceber que a força do vendo não influencia se teremos um jogo quando está nublado.
2. Raciocinamos sobre os fatos para obter a previsão
Após a máquina aprender com base nos fatos apresentados, podemos fazer previsões, que são apenas classificações com base no modelo criado (a árvore de decisão). Para prever, criamos uma nova estrutura, um novo objeto Tennis e preenchemos suas características (Features), não se importando com os rótulos (Labels), porque são este que serão previstos.
Veja o exemplo:
// Cria uma previsão com o que aprendeu sobre os dados
// Nesse caso, é passada uma nova informação para que seja previsto
// se ocorrerá um jogo de acordo com as previsões informadas.
IModel model = learned.Model;
Tennis t = new Tennis
{
Perspectiva = Perspectiva.Ensolarado,
Temperatura = Temperatura.Baixa,
VentoForte = false
};
Tennis predictedVal = model.Predict(t);
A seguir o resultado da previsão:

Pronto, só isso! Esse é o grande trunfo de Seth. Ele permitiu que com pouquíssimas informações sobre inteligência artificial, e com um objetivo claro em mente, é possível criar um algoritmo de aprendizado de máquina para prever/classificar informação sobre um conjunto de fatos apresentados.
Conclusão
Nesse artigo apresento como utilizar a biblioteca numl de Seth Juarez para criar um algoritmo de aprendizado de máquina supervisionado para prever se ocorrerá uma jogo de tênis com base nas condições climáticas.
Referências
- Supervised Learning;
- numl - a machine learning library for .NET developers
- A Tour of Machine Learning Algorithms
Bases de dados
Bases de dados para teste de aprendizado de máquina.